Hadoop and Virtualization? The Future Looks Bright
Dissecting big data with surgical precision and transforming it into valuable business intelligence regardless of its Velocity, Variety, and Volume is the key to successful IT decision-making. Yet, the problem with managing big data is the difficulty of getting it organized under a single infrastructure due to the incredible rate at which it is constantly growing. The pure size, speed of arrival, and diversity of the data, or the “3 Vs”, makes managing it a handful.
Velocity refers to the speed and frequency at which data arrives in real-time. Variety refers to the different kinds of data and it’s seemingly infinite attributes. Finally, Volume refers to the sheer size of incoming data; ranging from small Megabytes to colossal Petabytes.
So what tools can help up deal with the 3 Vs?
Traditional Virtualization distributes data into even more nodes within computer systems, allowing for increased storage capacity and faster data processing. Traditional Virtualization should not be confused with Data Virtualization; the process of creating a single, unified and simplified interface for accessing real-time (or near real-time) data sources.
Computational models such as Hadoop and Tableau have created proven methods of breaking down large data sets and deriving information.
The Hadoop framework is an open source implementation of the MapReduce on the Hadoop Distributed File System. HDFS is a file system (not a DBMS) designed to manage a very large number of files in a highly distributed environment. Hadoop allows you to break large data sets into smaller blocks and distribute them throughout various computer systems – called nodes – throughout Hadoop clusters. The purpose is to have the data scattered throughout thousands of individual machines instead of on large servers, allowing better resource management and faster data processing.
Tableau provides analytics against this data. It allows you to create intelligent rules and develop beautiful reports from your data.
Can Traditional Virtualization be combined with Hadoop?
Yes. With Traditional Virtualization, we can take this process even further and enhance flexibility. Instead of having one Hadoop cluster per local machine, we can have 2, 3, or even 4 virtual machine instances per node. So let’s say you’ve got 24 local machines (nodes), now create 4 virtual machine instances per node and you’ve got 96 nodes of computing power. Add more processing power, memory and storage capacity and performance numbers become very impressive.
Once you have all this data crunching power, applying Tableau to your data can give you some great insights.
Virtualization and Hadoop, the results are in
According to an article by ZDNet, running Hadoop under virtual instances outperforms local instances almost every time.
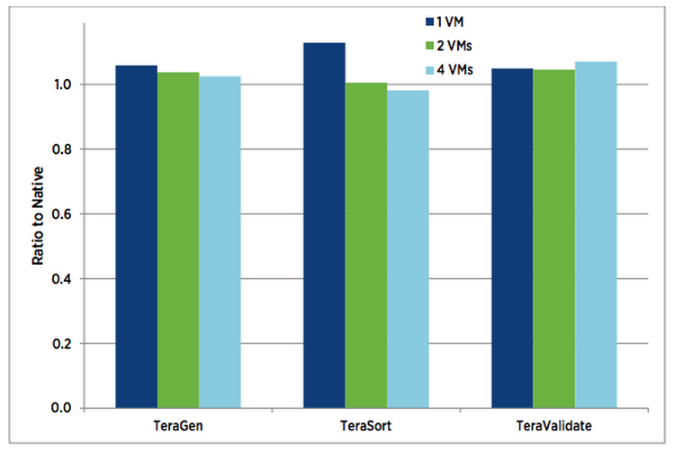
More tests results from VMWare, Amax, and Mellanox yield positive results; with instances of up to 4 virtual machines per node. As we can see the virtual instances outperform the local instances on separate occasions:
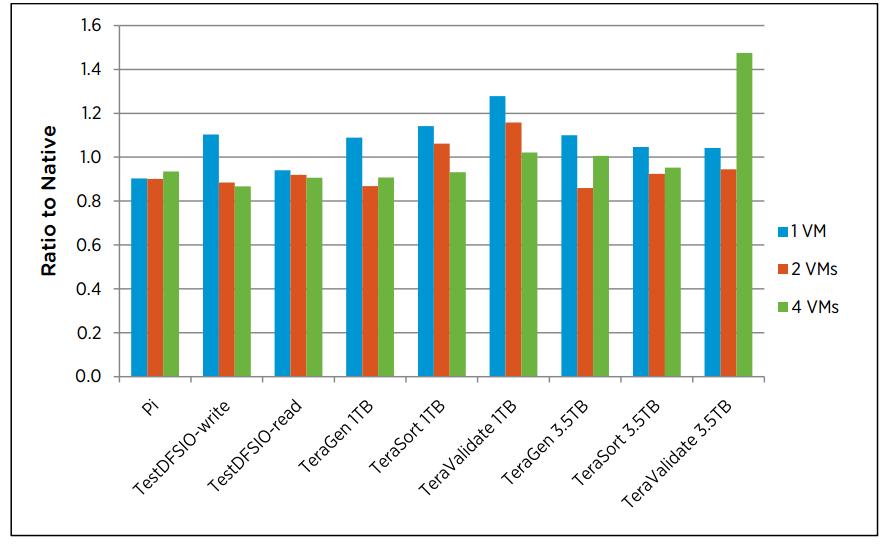
VMWare backs up their findings :
“It was found that the more powerful hosts give a larger advantage to multi-VM per host configurations: virtualized TeraSort is now up to 12% faster than the optimized native configuration.” – VMWare
Now, these implementations are new and still being tested, but the performance results yielded from recent tests are spectacular. While investing in data virtualization technologies is a super complex, costly, and time consuming process, in the long-run, this it has the potential to make big data less costly to manage and faster to process.
The future looks bright for the virtualization of Hadoop – using Tableau for analytics.